

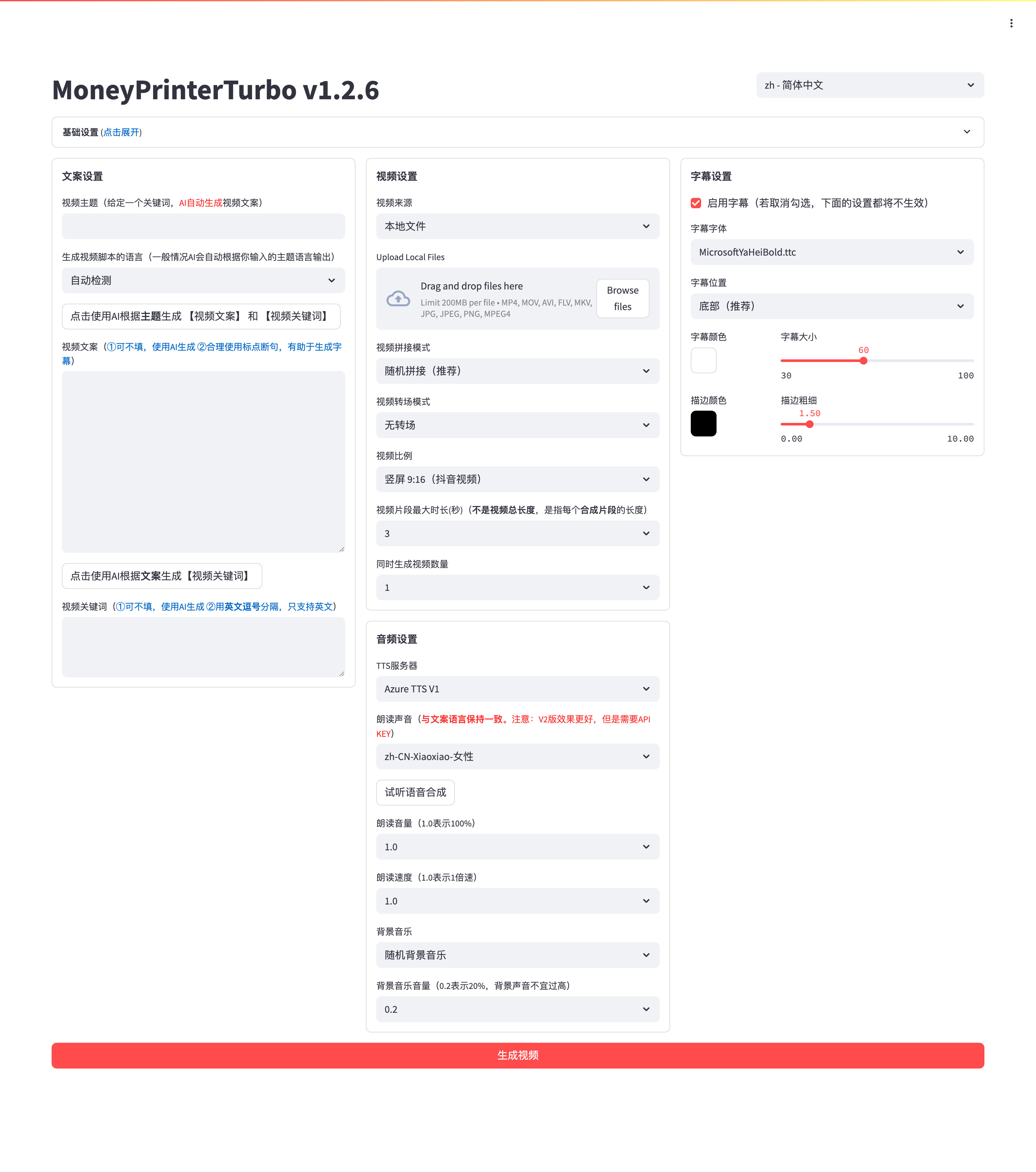
#15 - AI Agents Shaping 2025
Discover key insights, experiments, and lessons from testing AI agents in 2025 ⚡

Welcome to the 15th issue of AI Agents Simplified! 🎉

AI Agents in 2025: What’s Really Under the Hood?
AI agents aren’t just shiny demos anymore, they’re running real workflows, automating tasks, and even building apps. In this week’s blog, we break down the key components of modern AI agents (inspired by Chip Huyen’s excellent framework):
How agents perceive, plan, and act
The tech stacks that power them (tools + reasoning)
Why building a reliable agent is still hard in 2025
Plus: we walk you through how to build a simple agent using LangChain.
Want a clear overview of where AI agents are heading? This one’s for you.
AI Agents in 2025: Technical Insights and Frameworks

AI agents aren’t just a buzzword anymore! they’re doing real work. From scraping the web to managing business ops, agents are moving from “cool demo” territory into production-ready tools. And 2025? It’s the year these systems start running entire workflows, not just answering questions.
What I Learned Testing Dozens of AI Agents in 2025
After running dozens of real-world tests on AI agents this year, the lessons are clear and the future is specialized, collaborative, and deeply integrated.
Here are the key takeaways:
Specialized agents win: One-size-fits-all is out. Purpose-built agents outperform general ones.
Integrations matter: Agents that plug into Slack, Notion, CRMs, and APIs dominate.
Human-AI collaboration works best: Let the AI do the grunt work; humans steer and polish.
Ethics can’t be ignored: Transparency, privacy, and bias need serious attention.
There’s a learning curve: Prompt engineering and smart UX make all the difference.
Don’t overpay: Mid-range agents with focused features often beat pricey “enterprise” tools.
Multi-agent systems are the future: Synchronized teams of agents are already here and they’re powerful.
Read the full article to dive deeper into what works, what breaks, and how to build agents that actually deliver in 2025.
Lessons from Testing Dozens of AI Agents in 2025

The AI agent scene in 2025 isn’t just booming, it’s maturing fast. After putting dozens of AI agents through real-world tasks over the past year, one thing is clear: the days of generic AI assistants are fading. What’s rising in their place? Specialized, tightly integrated, and collaborative systems that get things done. Here’s what stood out.
📰 What Happened in the Last Week?
Microsoft Hosts Elon’s Grok on Azure
In a surprising twist, Microsoft is now hosting Grok - Elon Musk’s LLM from xAI - on Azure. Despite Elon’s public beef with OpenAI (which Microsoft heavily backs), this move shows how fast the AI ecosystem is evolving and how strategic partnerships often win over rivalries.
Grok is built for scientific reasoning and accuracy, making it a strong contender for powering next-gen AI agents. With Azure’s infrastructure, developers now get scalable access to a model designed for context-aware and evidence-driven outputs. Expect Grok to start showing up in research tools, dev workflows, and maybe even support systems where precision matters.
What this really means? Cloud platforms like Azure are becoming AI agent playgrounds, and more choices for developers = faster innovation. Still, it raises some questions, especially around data privacy and cloud dependency.
Bottom line: Microsoft-xAI is a big signal. Grok’s now in the hands of more builders, and that's good news for agent devs who care about scientific performance over hype.
Google’s AMIE Is Redefining AI in Healthcare
Google just dropped a major update on AMIE (AI Medical Image Examiner), a specialized agent trained to analyze medical scans X-rays, MRIs, CTs with near-clinical accuracy. It spots abnormalities, marks up key areas, and helps doctors make faster, more informed calls.
Built on massive datasets and years of research from DeepMind, AMIE is a real-world example of a focused AI agent that’s not trying to do everything, just one thing incredibly well. It integrates directly into existing clinical workflows and augments (not replaces) doctors' decisions.
Why it matters? AMIE shows the true potential of domain-specific agents. Trained right, these systems can change lives starting in medicine, but easily extending to law, engineering, and beyond. Of course, adoption will need to clear regulatory and ethical hurdles first.
Bottom line: AMIE is a blueprint. Specialized AI agents trained on industry-grade data can outperform general models, especially in high-stakes fields like healthcare.
🔮 Cool AI Tools & Repositories

📃 Paper of the Week

This week’s spotlight is on “Paper2Code: Automating Code Generation from Scientific Papers in Machine Learning” by Minju Seo et al. a seriously impressive step forward in reproducibility for ML research.
At its core, the paper introduces PaperCoder, a multi-agent LLM system built to convert ML research papers into working codebases automatically. That’s a game-changer when you consider that only 21.23% of 2024’s top-tier ML papers came with any code at all.
Instead of researchers spending hours (or days) reverse-engineering algorithms from dense PDFs, PaperCoder handles the heavy lifting producing modular, executable repositories straight from paper text.
How It Works: A Quick Breakdown
The Problem: Most ML papers don’t share code, making reproducibility a nightmare. PaperCoder solves this by auto-generating the entire codebase from scratch no pre-existing code, no hidden APIs.
The Framework: A clean 3-stage pipeline:
Planning: Designs architecture, generates UML diagrams, maps out dependencies, and creates config files like
config.yaml.Analysis: Breaks down each file's function, input/output, and key constraints, directly from paper text.
Generation: Produces modular, dependency-aware code, respecting the planned execution flow.
Results That Matter
Benchmarks:
Paper2Code: Tested on 90 papers from ICML, NeurIPS, and ICLR 2024 with available GitHub repos.
PaperBench: Evaluated on 20 more papers from ICML 2024 for deeper validation.
Outperforms top baselines like ChatDev and MetaGPT, both in human evaluations and automated metrics.
Performance:
77% top rank in human evals.
85% of judges found the generated code genuinely useful.
Only 0.48% of lines needed fixes to run.
Nice article
Funny!